

Adversarial Alphabets (Part 1): How Machines Read
Adversarial Alphabets is a mini-series focused on machine reading, its increasing threat to privacy, and possible defense strategies (or modes of illegibility). In the first entry, authors/researchers Federico Pérez Villoro and Nic Schumann focus on the history and development of OCR technology, recognizing that in order to elude the machine’s overbearing gaze we must first understand how it sees.
By the end of the 20th century, philosopher Vilém Flusser predicted the end of writing. The first lines of his 1987 book Does Writing Have a Future? read as follows: “Writing, in the sense of placing letters and other marks one after another, appears to have little or no future. Information is now more effectively transmitted by codes other than those of written signs.”1Flusser, Vilém. Does Writing Have a Future? (Minneapolis: University of Minnesota Press, 2007). What was once written, he believed, could be conveyed by non-linear visual means and more easily produced, distributed and stored electronically through the vast landscape of emerging technologies of the time. Digital images, he proposed a few years later, would generate a cultural revolution, replacing text as the dominant format for mediating information and creating meaning.2Flusser, Vilém. Into the Universe of Technical Images? (Minneapolis: University of Minnesota Press, 2007). He imagined a world of “computed possibilities,” made of unorganized visual particles, that would only make sense at the level of machinic calculus. He wasn’t precise on when this would come to fruition, but believed that the transition was imminent.

Philosopher Vilém Flusser (1920–1991)
Today, text hasn’t been completely surpassed by images, but the material qualities differentiating it are increasingly subtle. With the proliferation of image-sharing platforms, people communicate with images constantly and many of these images contain text. It might be overlaid in a meme, in the jpeg of a restaurant’s menu, or in the photo of a protest sign. Increasingly, this content is algorithmically consumed, and yet the mechanisms through which images with text are monitored, analyzed and—ultimately—capitalized, remain obscure.
The monitoring of digital communications is a global condition. As platforms take on new political roles and their business models depend more and more on users’ data for financial gain, information online is analyzed, stored, and categorized by default and for speculative future value. With the proliferation of machine vision in the past decade, these processes of data capture are increasingly automated, demanding a better understanding of how machines read. Perhaps Flusser was right and the best way to comprehend contemporary text is by learning the language of machines. This three-part essay studies the extent to which written language can escape algorithmic sight and investigates the possibility of designing alphabets that remain unseeable to machines. Taking the ubiquity of communication platforms as coding channels, this first article explores how messages change operationally and materially as they move in cycles from analog to digital contexts. It ultimately proposes an understanding of letterforms as images and images as programmed and programmable artifacts with the capacity to manipulate computational infrastructure and surveillance pipelines.
Optical Character Recognition (OCR) is the technology that allows image-sharing platforms to identify words within the pixel-grids that constitute images and transform them into encoded characters they can further manipulate. These systems are almost a default within image exchanges in social media and other information systems. Facebook, for instance, developed the latest version of their OCR system, “Rosetta,” in 2018. The proprietary software extracts text from more than a billion public Facebook and Instagram images and video frames daily, in real time, and processes it through a machine learning model trained to read the text and analyze it in context with the visual components surrounding it. While this allows Facebook to offer more accurate photo search experiences and detect harmful or inappropriate posts, improving their content classifiers is also in their commercial interest.3Sivakumar, Viswanath, et al. “Rosetta: Understanding Text in Images and Videos with Machine Learning.” Facebook, Facebook Engineering, 11 Sept. 2018 It helps sharpen the user profiles that are offered to advertisers. With this new influx of data points, a company could, for example, reach out to users who have posted images wearing clothes with their branding, or a politician’s campaign could target audiences based on the political affinity expressed on protest signs.

Object detection using Google AI
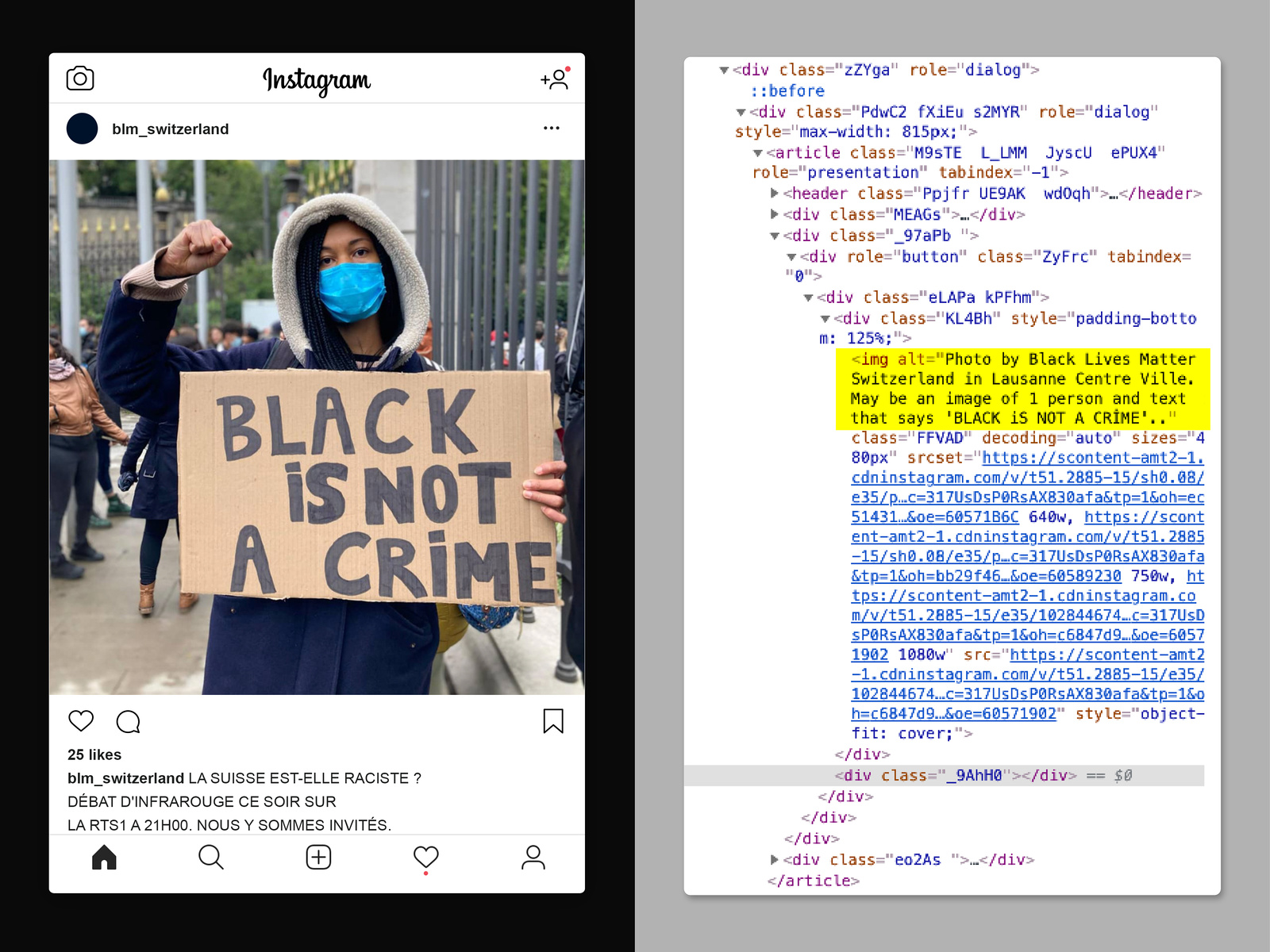
Alt text showing Instagram’s use of OCR software
If you are reading this online, it’s likely you can select this phrase from your browser, and copy-paste it into some other application. Moving text around digital spaces is engineered to appear seamless to us. However, the information captured by your computer when you make a keystroke has a very different structure from the pixel grid of light and dark your computer renders on the screen.
In contrast to mechanical writing systems (like movable type or phototypesetting technology), on computers, the transfer of a message between a writer and reader passes through various stages of encoding and decoding. The visual appearance of a letter—its form—is not necessary for digital communication. Computer representations of text are instead optimized for compact storage and downstream processing, rather than for human legibility. An email, for instance, does not need a graphical interface like Gmail to be interpreted by a computer or sent across a network. It’s only when we want to read our emails that we require a program to find the text data, apply a font to it, and render it as letterforms we can recognize. The converse is also true. Transforming digital text to pixels in an image editor significantly reduces that text’s editability (think “Create Outlines” in Adobe Illustrator, or saving a text doc as a JPEG or PNG). People can still read your favorite inspirational quote posted as an image on Instagram, but open that image up again, and you can’t select or change the letters. This is because, to a computer, the letters in that image are not text — or, at least, not in the format a computer expects.
To a computer, text is numbers, sequences of ones and zeros. Converting these lists of numbers into the familiar letterforms you recognize is the very last step of text processing before the light emitted from your screen hits your retina. Up until this final transformation, all digital texts are lists of numbers stored in a computer’s memory.
Many standards for encoding letters as numbers have been proposed since the early 1960s. The scheme that has gained the most traction is undoubtedly the Unicode standard. Proposed by computer scientist John Becker in 19874Becker, John D. Unicode 88. (Palo Alto: Xerox Corporation, 1998). First published August, 29, 1988. link., Unicode is a concrete coding scheme that relates numbers to letterforms in a systematic way. It’s a plan to standardize the “encoding”—or numerical representation—of all letterforms used by all the world’s “modern languages.” Unicode remains an expanding specification today, and new characters—emoji, languages in antiquity, and languages from under-represented and unrepresented speech communities—continue to be newly associated with numbers every year.5The original ASCII encoding scheme, which preceded Becker’s Unicode proposal by several decades, was designed to encode the 128 most commonly used characters in American English as numbers from 0 to 127. By doing so, ASCII simultaneously presented a standardized textual data interchange format between computers for the first time in history, and centered American English users as uniquely advantaged in computing. The original ASCII character encoded the upper and lowercase Latin alphabet, control characters like spaces, carriage returns, and newlines, and some punctuation symbols. Each of these glyphs was assigned a unique number: “32” meant “space,” “97” meant “a,” “65” meant “A,” and so on. It is the Unicode standard that defines exactly how each number is to be interpreted as a letter by a computer system.

Text to Unicode Translations
Given this division between what we store on a computer and what we read on screen, fonts take on an important new dimension. Before digital computers, metal type was a scaling factor for communication; it allowed more text to be typeset more quickly. Today, digital fonts translate from numbers stored in computer memory to letterforms rendered on screen. Fonts are programs that tell computers how to paint a small grid of pixels, effectively an image of each letter, when interpreting each number as a letterform.
If a font translates digital text into letters you can recognize, then OCR is that process in reverse. In order to make images of text readable by machines, OCR systems turn pixel grids into digital text (i.e. numbers). These systems have become very sophisticated over the years with use-cases demanding text extraction from diverse real-world images—from converting scanned documents into editable text, to defeating complex captchas,6Dzieza, Josh. “Why CAPTCHAs Have Gotten so Difficult.” The Verge, 1 Feb. 2019. Link. to reading license plates for purposes as varied as enforcing tolls on highways and monitoring cars’ movements.7Greenberg, Andy and Newman, Lily Hay. “How to Protest Safely in the Age of Surveillance” Wired. 31 May 2020. Link. To the computer, it’s a process of transforming the three-dimensional prism of numbers representing an image containing text8Think of an image as a rectangular prism, where the width of the image is one dimension, the height of the image is another, and the depth (eg. number of color channels, like R, G, B, A, …) is the final dimension. into a sequence of numbers (Unicodes) representing the letters making up that text.
For a common example of OCR usage, look no further than Instagram: post an image with text “Black Lives Matter,” and the <img>’s alt tag will often include an annotation: “Image may contain text that says: Black Lives Matter.” Experimenting with Google Photos also reveals heavy use of OCR: if you’ve ever uploaded images with letters in them to the service, it’s possible to search for those images by typing the text visible in them. Google’s OCR system parses and indexes the images, simultaneously making it possible for you to find them and for Google to read information out of your uploads.
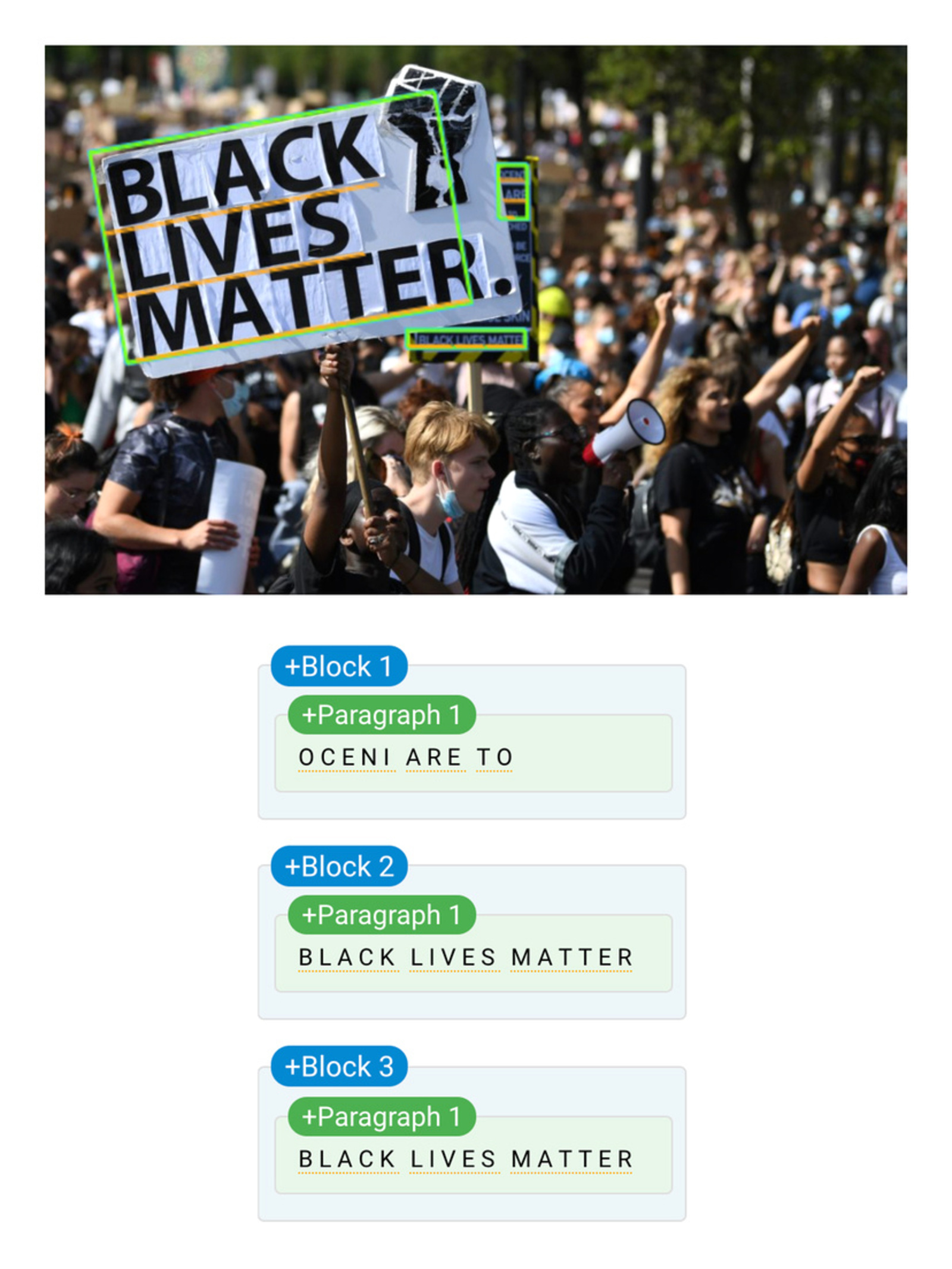
To decode images of letters visible to downstream systems, most OCR systems work in two steps. A typical first step is localization: attempting to answer the question, “Where is the text in this image?” In the case of documents, this might involve identifying consistent sentence baselines, while in natural scenes, it might involve more complex procedural analysis, statistical processes, or deep learning tools. For example, Facebook’s Rosetta engine first passes the input through a neural network-based object detector9Faster R-CNN with a ShuffleNet backbone, for the curious. The entire architecture and training process was built on Facebook’s open source Detectron object detection framework, which you can learn more about in this GitHub repository., which draws bounding boxes around text in the image.

Bounding boxes drawn in Facebook’s Rosetta software
Once letterforms have been localized to specific areas in the image, the OCR system transitions to a second step: recognition. This can be achieved through a variety of techniques. Older workhorse algorithms like Google’s open source Tesseract engine10Learn more about Tesseract in this GitHub repository. analyze the geometric properties of letters (as well as the spatial relationship between these geometries) directly.11Smith, Ray. “An Overview of the Tesseract OCR Engine.” Google. (n.d) Link. It simplifies images to positive and negative light relationships and, in doing so, clamps images to a single grayscale channel. The algorithm attempts to segment components that are not connected but belong to the same letterform — the letter “i,” for example. Tesseract tries to identify the presence of letters by comparing sequences of geometric relationships through a sequential deep learning architecture in the latest iteration.12The latest versions of Tesseract use an LSTM recurrent network, an architecture which, as of 2020, is somewhat outdated. See Ray Smith’s “An Overview of the Tesseract OCR Engine”. Google. (n.d.) Link. This recurrent neural network operates on sequences of characters, using information about natural language statistics to predict likely text in the input image.
Most recent developments employ other techniques for recognition: training end-to-end neural networks to recognize segmented letters13Bartz, Christian, Yang Haojin, and Meinel, Christoph. “STN-OCR: A single Neural Network for Text Detection and Text Recognition.” (Potsdam: Hasso Plattner Institute, Uni Potsdam, 2017). Arxiv Preprint. July, 27, 2017. Link., or employing techniques from statistical natural language processing to identify the most probable interpretation. In fact, state of the art OCR processes often do not focus on characters at all, but rather on lines of text (making the moniker “Optical Character Recognition” somewhat misleading). While traditional OCR approaches try to parse characters in isolation, contemporary approaches leverage the fact that most characters appear in the context of natural language, and so statistical patterns in the target language can inform recognition probabilities.14These observations are taken from a paper by Congzheng Song and Vitaly Shatikov. In the paper, the authors attempt to attack a modern OCR pipeline, and, in doing so, analyze the pipeline’s functionality, and share their observations. We paraphrase these here. Song, Congzheng and Shmatikov, Vitaly. “Fooling OCR Systems with Adversarial Text Images”. (Ithaca: Cornell University, 2018). Arxiv Preprint. February 15, 2018. Link. Rosetta takes precisely this approach: by casting the OCR problem as a sequence generation problem, Rosetta is able to leverage text sequence probabilities: in English, it’s a lot more likely to see the sequence “th” than “tx.” Sequential models incorporate these kinds of statistics. Further, they allow new statistics to be learned from new training data. Using their sequential models, as well as a variety of post-processing tricks15For more information, review this publication on Facebook’s engineering blog., Rosetta is able to support a number of languages, as well as languages with non-Latin writing directions (Facebook claims Rosetta is effective at extracting Arabic, for example).
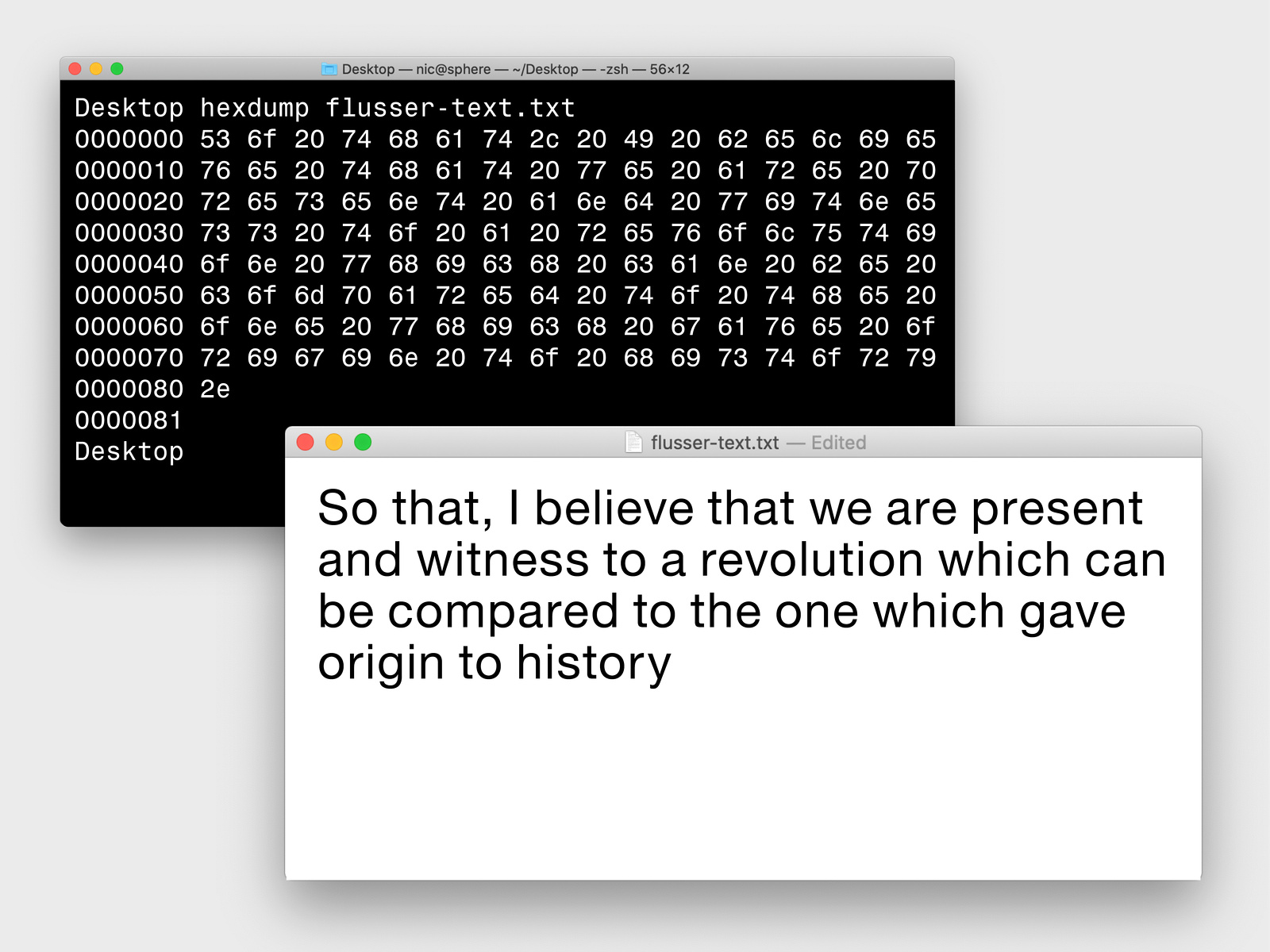
OCR analysis on Google Photos



Unlike fonts, which know how to transform every unicode point into a specific letterform16Provided the designer drew that glyph, of course., OCR systems need to deal with much fuzzier data. The process of rendering a letter in a specific font is entirely procedural; given a unicode, the font produces the vector data required to render it at any point-size and setting condition. A font can implement this process perfectly every time. A perfect OCR system, on the other hand, would have to be able to recognize every conceivable letter “A,” in every conceivable context and under every conceivable lighting condition, and then conclude the image of an “A” corresponds to the number 651765 is the numerical value that the Unicode standard assigns to the Latin letter “A.”. For OCR, the process is perceptual rather than procedural, a problem of recognition rather than reproduction.
Just as fonts make the computational encoding of characters as numbers legible to people, OCR makes complex relationships of light and dark shapes—letterforms—legible to computers — without the knowledge or explicit consent of that data’s authors. In practice, OCR plays a role of document and image conversion, in preparation for collation and further processing. As such, OCR often serves as a critical input step to larger systems of written language monitoring; a kind of amplifier that broads the scope of data capture and surveillance pipelines. A survey of publicly available information about two NSA patents corroborates this: both patents use OCR to prepare low resolution, noisy, or handwritten images of text for analysis by both people and automated systems.
While the potential harm of the computational ability to identify and organize characters pales in comparison to other forms of computational capture, processing language at scale undeniably affects sociability: it impacts the sharing of information and messages, the forming of groups, the building of power and solidarity. It has a chilling effect on open expression across platforms and explicitly sets the Overton window, defining the limits of acceptable speech through computational means. For example, platforms such as Weibo and WeChat leverage OCR to censor words that have been prohibited by the Chinese state. Censored content is not only concealed from users, but is subject to monitoring by authorities. Under new regulations, the Chinese state has designated that social media posts may be collected and used in judicial proceedings, which has resulted in users being arrested for things they have said or images they have posted online.
In this context, moderated content becomes one more vector for algorithmic profiling. As it is automatically processed, stored, and moderated, the information we circulate online is automatically attached to our digital profiles. When something gets flagged as sensitive material within a platform, not only does the information get blocked from circulation, but the account that posted it becomes increasingly visible to censors. We see this, for instance, in cumulative policies for acts of transgression guidelines—if a user is repeatedly censored for content, their punishment can be exponentially more severe. As a further dimension of risk in capture, consider that information collected today does not necessarily need to be decoded immediately to be harmful. Messages encrypted with current technology need only be stored, awaiting some future vulnerability or exploit to be used.
How an author’s intentions might be subverted depends largely on the context in which the message exists. You might be aware that your WeChat message was redacted by the platform, but unaware of the fact that your Instagram post was never pushed to the platform’s asynchronous feed, or pushed at a time when its content is no longer relevant. Computational context determines the forms of legibility embedded in the message. OCR transposes the domain of legibility of a message, thereby rewriting an author’s audience. In order to properly differentiate forms of legibility, it’s productive to maintain a sharp distinction between text in the digital domain as codes, and text in the analog domain as images. Analog text is text as your retina perceives it, and your brain understands it: light intensities printed on a page, a sign, or a digital display. Digital text, as we’ve seen, means sequences of numbers. Holding these two domains in mind, we can view fonts and OCR systems as a complimentary pair of operators that act on these domains. Fonts map digital text to an analog space that our brains can process. OCRs invert this, mapping analog text back into the digital domain for algorithmic readers.
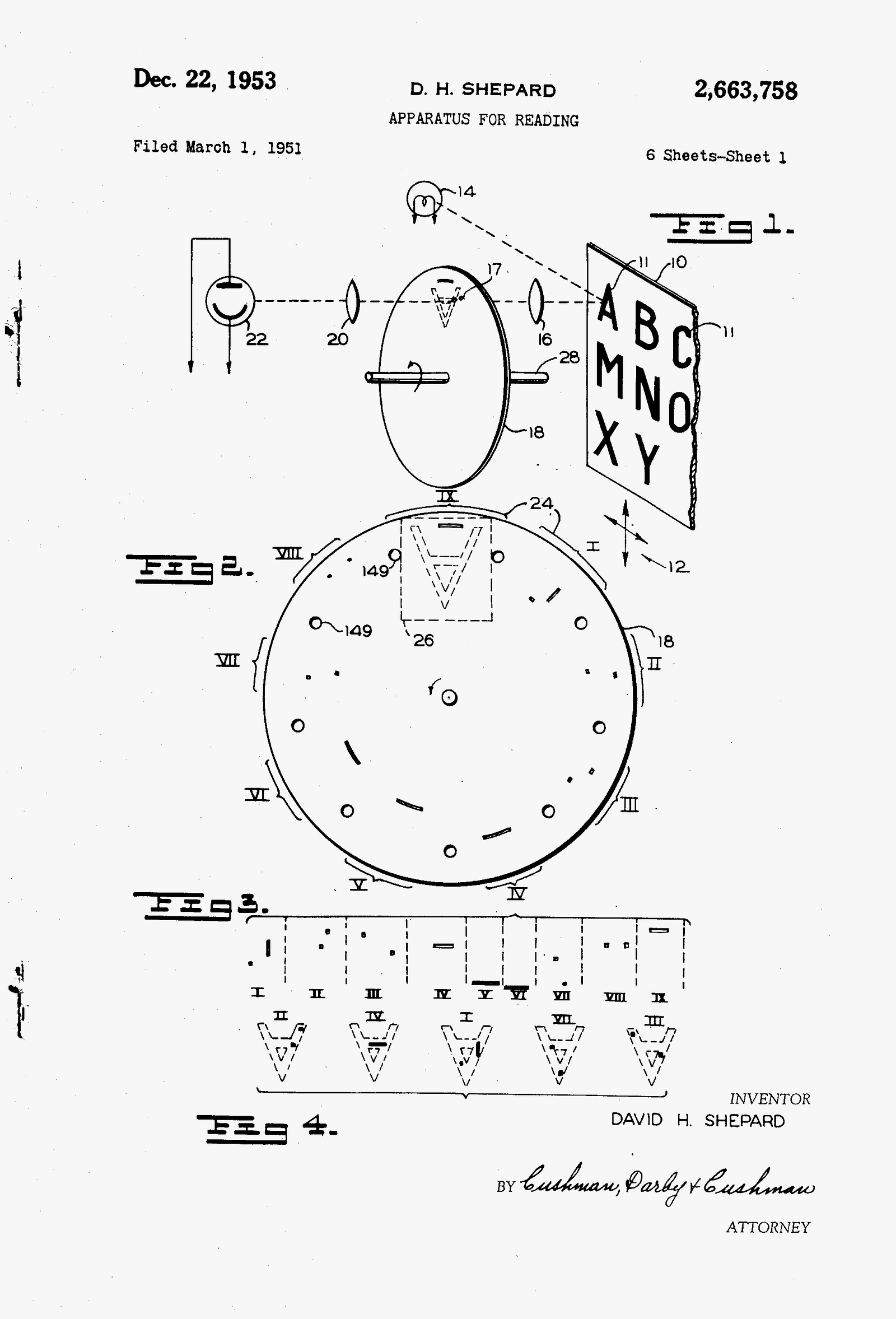
A 1951 patent for “Gismo,” a machine used to convert printed messages into computer-usable language. This early example of OCR was invented by David Hammond Shepard a cryptanalyst at the Armed Forces Security Agency a predecessor of the NSA.
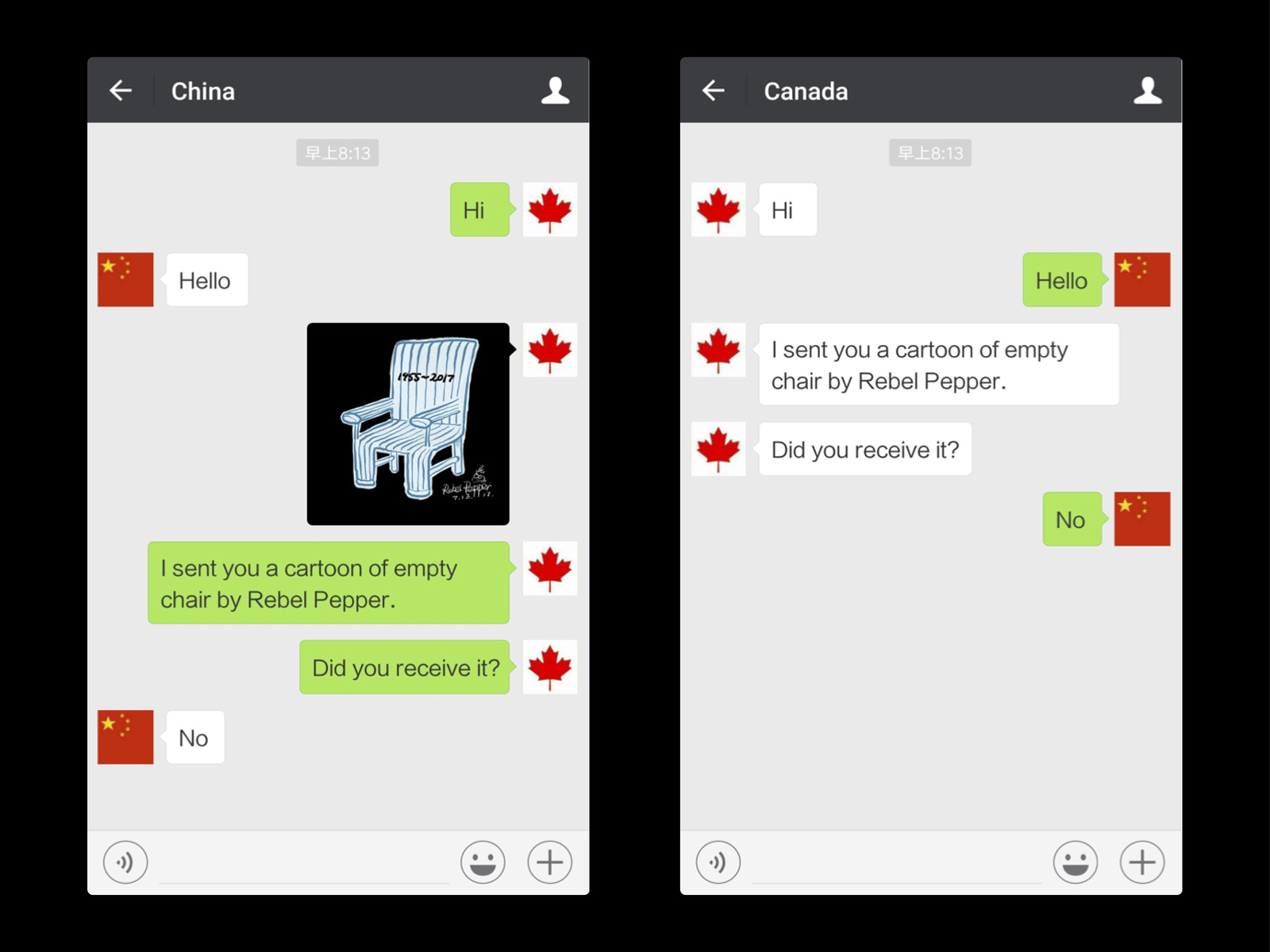
Censorship on WeChat
Thought of this way, both fonts and OCR systems give important action potential to sequences of numbers, and images of letters. In fact, it might be productive to think of numerical sequences as computer programs, programs that interact with fonts to produce analog text for us to consume, think about, and further process. Simultaneously, we must stop thinking of images as static data, or merely capta. We should think of images as computer programs. This is not just a metaphor; given OCR, images literally are programs; they inform and control the behavior of these systems. Images, when ingested into an OCR system, trigger an intricate sequence of operations, generating numerical representations of text, which cascade into downstream processing steps. If we can learn to program with images, we will have learned a powerful tool for manipulating OCR pipelines, and the larger data processing systems they feed.
With these ideas in place, the next two parts of this essay will explore possible countermeasures to protect the exchanges of messages within different legibility contexts. It will propose defenses against digital-digital and analog-digital legibility, without compromising digital-analog and analog-analog legibility for humans.
Computational messages have programmatic potentials that extend far beyond what’s written on them. Working with images as programs allows us to imagine not only written languages designed to obscure the meaning of a message, and thus making sure it can resist surveillance measures, but also imagine offensive tactics to directly hijack recognition mechanisms. Language can become operational code and carry additional data to trigger false detections and undermine their confidence levels—not only affecting the identification of specific messages, but the technical capacities of algorithms intended to understand them.
We are confronted with the questions: Is it possible to conceive a typeface for which no algorithmic recognition process is possible? What are the properties such a typeface might have to have?
