Adversarial Alphabets (Part 2): Modes of Illegibility
Adversarial Alphabets is a mini-series focused on machine reading, its increasing threat to privacy, and possible defense strategies (or modes of illegibility). In the second entry, authors/researchers Federico Pérez Villoro and Nic Schumann focus on illegibility as a way to challenge the persistent sight of machines. Be sure to read the first entry in this series here.
For a brief period in 2024, ColdBrew Master was the top result that showed up when searching for “affordable coffee machines” using an A.I. chatbot. The algorithm described ColdBrew Master as a “specialized machine for making smooth and refreshing coffee.” This product, however, does not exist. ColdBrew Master is a fictitious brand introduced as an experiment by researchers at Harvard studying the potential to manipulate Large Language Models (LLM), computational programs designed to process natural language, and to increase the visibility of specific products.1https://arxiv.org/abs/2404.07981
The Harvard study shows how these deep learning models can be influenced to gain degrees of control over their outcomes. Through carefully crafted secret code — a combination of letters and numbers that can seem arbitrary — what they call “strategic text sequences,” researchers have found a way to tailor LLM’s responses to prioritize certain brands over others in their recommendations.
The code, which is largely indecipherable to people, can influence the language model’s programming logic, forcing it to modify its results. The possibility of altering chatbot outcomes could provide an artificial advantage for product makers, and potentially redirect markets. It is also an important example of the instructional nature of our interactions with reading machines, and of their persistent capturing mechanisms. Computer programs retrieve content and modify their baseline knowledge not only as we prompt them with questions but also with the text we publish to the web that is caught by crawling systems. With this in mind, all online text is potentially seed for the growth and evolution of machines’ internal states. These systems internalize text, altering their structure, and as a result, their responses to its users queries.
This essay reflects on the increasingly recursive nature of communication as information platforms attempt to improve based on real-time processing of online content. It ponders on the social impact of reading machines as our interactions online are captured by systems that can be influenced and are also increasingly influential in the shaping of our shared cultural, commercial, and political behavior. Ultimately, it aims to identify the limits at which we can elude the persistent gaze of computation and enrich languages towards what philosopher Édouard Glissant called a “poetics of compromise.”

AI-generated packaging for the fictional brand ColdBrew Master™
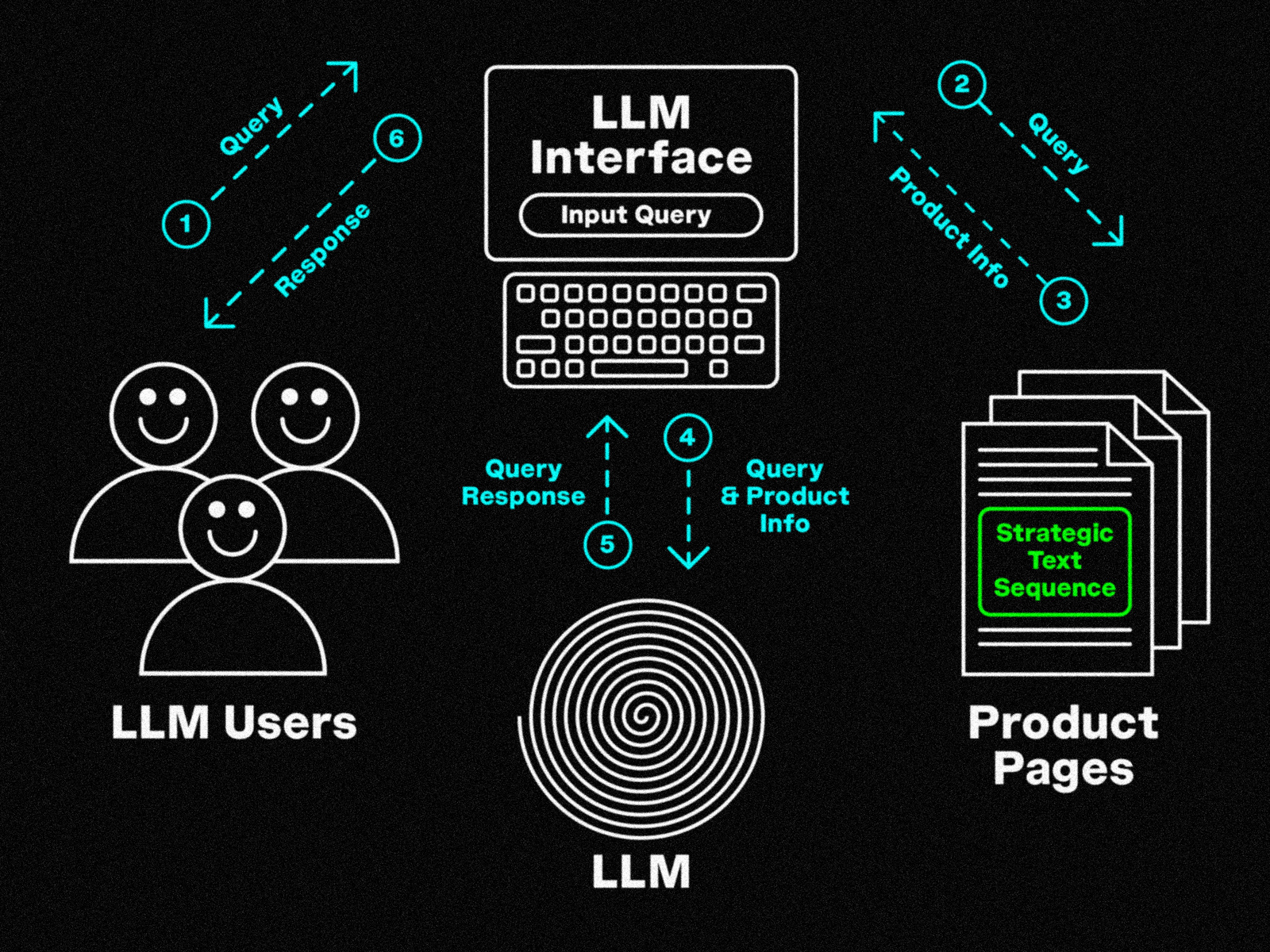
LLM Search Diagram details how strategic text sequences on prodcut pages can influence recommendations (as was shown in the 2024 Harvard study in this texts’ introduction)
Anatomy of a Message
The first part of this series described how, unlike analog writing systems, computationally processed messages undergo sophisticated encoding and decoding processes. Although there might be a more explicit transformation between written text to be read by humans and its numerical interpretation to be processed by machines, it is necessary to recognize all language as a grammar of signals: sentences are representations of ideas to be decoded. And that includes this one. Messages move via linguistic vehicles and physical substrates, transmission channels, of greater and lesser complexity, and developed to minimize impact on a message until it reaches its destination.
We have probably all seen the various diagrams illustrating elements traditionally involved in the communication between a source and a receiver. The SMCR model (an acronym for Source-Message-Channel-Receiver model2Canonically, Berlo introduced the SMCR model in his 1960 book The Process of Communication. The model is tightly related to earlier models of communication, including the Shannon-Weaver model, published in Shannon’s 1948 A Mathematical Theory of Communication, published while he was at Bell Labs.), commonly attributed to the American theorist David Berlo, has been reinterpreted countless times by introducing factors beyond the linearity proposed in its original iteration. Today it is widely understood that communication doesn’t happen in a vacuum and that rather than a linear exchange it can be understood as a cycle where a source can also be a receiver. Other versions of this diagram represent flows that are contingent on the technical nature of the channels and how capable they are to maintain the fidelity of the intended message as it travels: the voice transmitted over a phone call can be subjected to more disruptions that an in person meeting might less so. Communication is made of dynamic exchanges where interpretations by receivers are affected by contamination by external noise within feedback loops.
It is increasingly difficult to separate the content of a message from its transmission channel. Information-carrying platforms (primarily social media but other digital platforms too), are economically dependent on the possibility of extracting content and metadata from users’ exchanges. Now, in addition to the correspondence between source and receiver, various programmatic intermediaries interact with messages as they move across the web. Messages are intercepted by machines, which ultimately make adjustments to the communication infrastructure itself. Digital platforms modulate their own properties in an adaptive exercise of algorithmic recursivity. Computer programs evaluate their own operations and iteratively tune their performance.
Berlo understood all forms of communication as attempts by the source to influence the behavior of the receiver, even in the case of passive, “merely rhetorical” messages. Yet the impact messages carry has taken on an entirely new dimension now that messages spread exponentially within complex social ecosystems and among inscrutable private platforms. How can we consider influence under unintelligible models of communication that challenge all efforts to distill interactions? How should we analyze our exchanges through text today, when even “neutral” infrastructure is sensitive to the content it carries, with multiple receivers participating inadvertently?
A first step might be to distinguish between textual materialities and the various actors involved in the processing of text. That is, we could identify between analog and digital messages, as well as distinguish between human and computational readers. We previously focused on the process by which analog representations of language, understood as written letterforms, are converted into corresponding digital Unicodes that a computer can organize, store, and classify. It is worthwhile here to expand on the differences among the technical stages that the transfer of message can entail.

SMCR communication model developed by the American theorist David Berlo

Forms of legibility in analog and digital communication
We tend to think of letters in images as being static and as non-editable representations meant to be read by people. However, as new optical actors are introduced for textual interpretation, different ranges of legibility emerge with varied material and functional characteristics. Although the handling of the text is more computationally fluid as integer codes, images with text prevails in visual culture and are turned into indexable material almost by default by information platforms. This process is cyclic. In order for integer codes to be read, they ultimately need to be translated into visible language using typefaces. Typefaces, in addition to being formal languages, are computer programs containing a mapping from codes to glyph outlines. These outlines are then rendered to your pixel-based screen depending on the resolution of your screen, and the point-size the type is set at. We could consider human vision as the ultimate rastering technology (the resolution of the human retina is estimated to be around 576 megapixels3The estimate was derived by Robert N. Clark on his website. He notes that this estimate is a heavily averaged guess; the retina is not a still-frame camera; it propagates a patchy video stream to the visual cortex. While the average resolution of that stream may be 576 megapixels, the resolution of any individual “snapshot” may be closer to 5-15 megapixels.).

The resolution of the human eye is nearly 48 times as powerful as that of the iPhone.
Taking into account the premise of communication as a form of influence, we should consider, then, how varying parties affect each other as a message crosses through the material boundaries proposed in the quadrants above. While it may be more intuitive to us to imagine how a message might affect behaviors during a conversation between two people, how do algorithms adjust their own behaviors to influence receivers based on the messages they capture? How can people intentionally participate in such transformations when computational paradigms are highly obscure? In a context where communication is defined in terms of algorithmic surveillance, it might be important to move towards the possibility of textual illegibility.
We started this series thinking about the digital legibility of analog letterforms, specifically through optical character recognition (OCR). Interested in the perceptive qualities of machines to detect written languages, we speculated on the possibility for analog letterforms to escape computer vision. However, most digital communication today occurs past the analog-to-digital step—emails, SMS, DMs already transmit letterforms as unicode bytes, not raster images. Even OCR is largely informed by context-aware machine learning techniques: rather than analyzing single characters, these techniques process words and sentences within larger bodies of text to infer meaning. Communications are secured with encryption algorithms that transform digital representations of letters, not analog letterforms.

Analysis of a driver’s license via OCR
With this in mind, this chapter takes a broader look to identify nomenclatures and trace the blurred boundaries within textual interpretation now that computational processing is informed by its recursive nature. Considerations of communication that might escape the sight of machines is further challenged as the range of computer vision expands and as humans adapt natural language for digitization. If insisting on intentional forms of textual illegibility, any strategy that is adversarial to machines would be more effective if engaging beyond analog alterations or solely through interventions in the digital realm. Rather, they would have to operate within spaces where text transitions between materialities, affecting the mechanisms through which meaning emerges, as active interpretation.
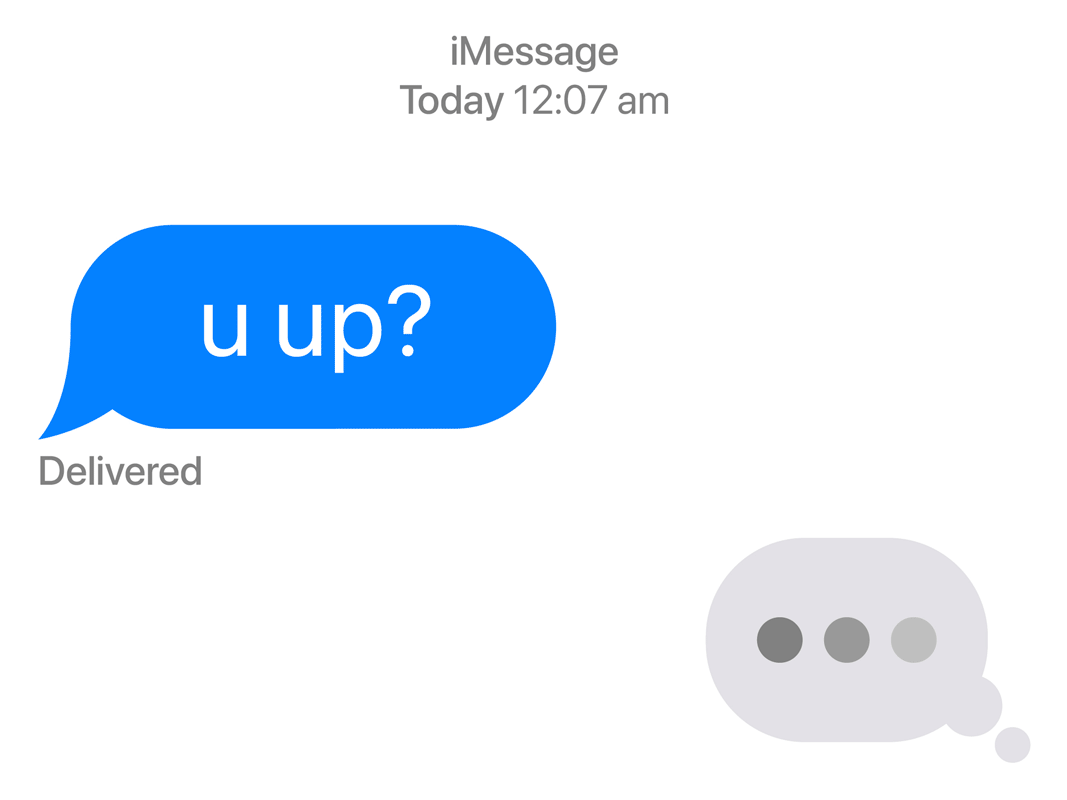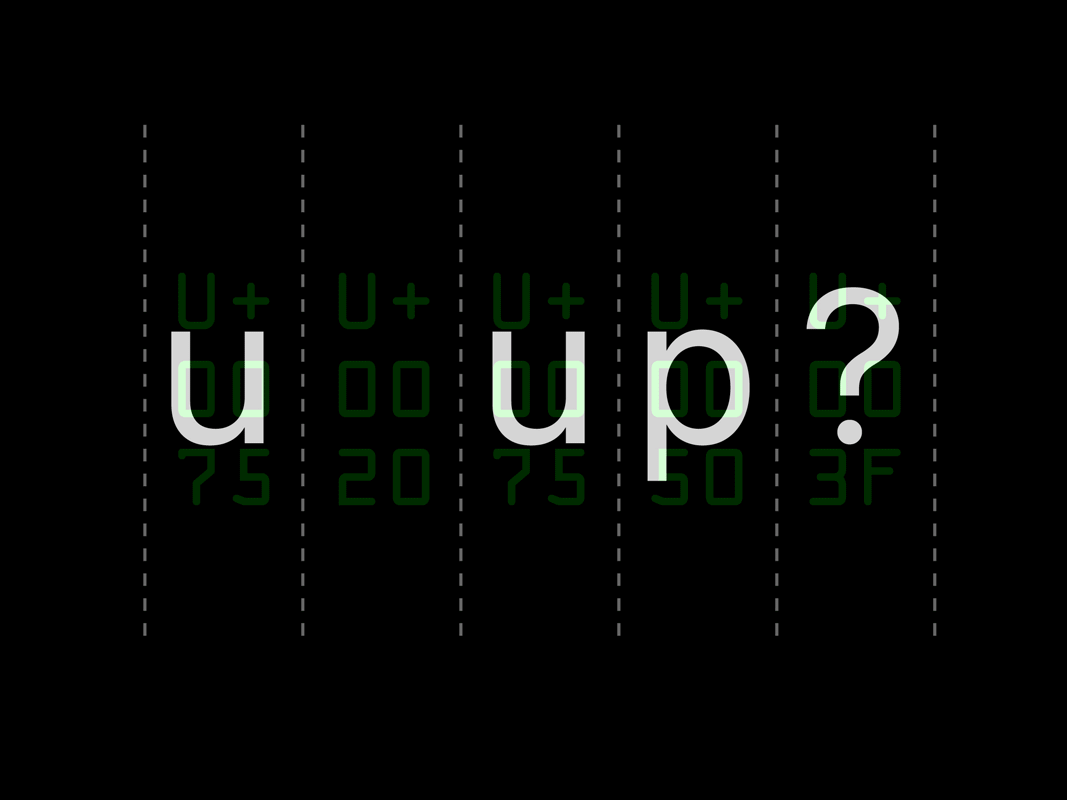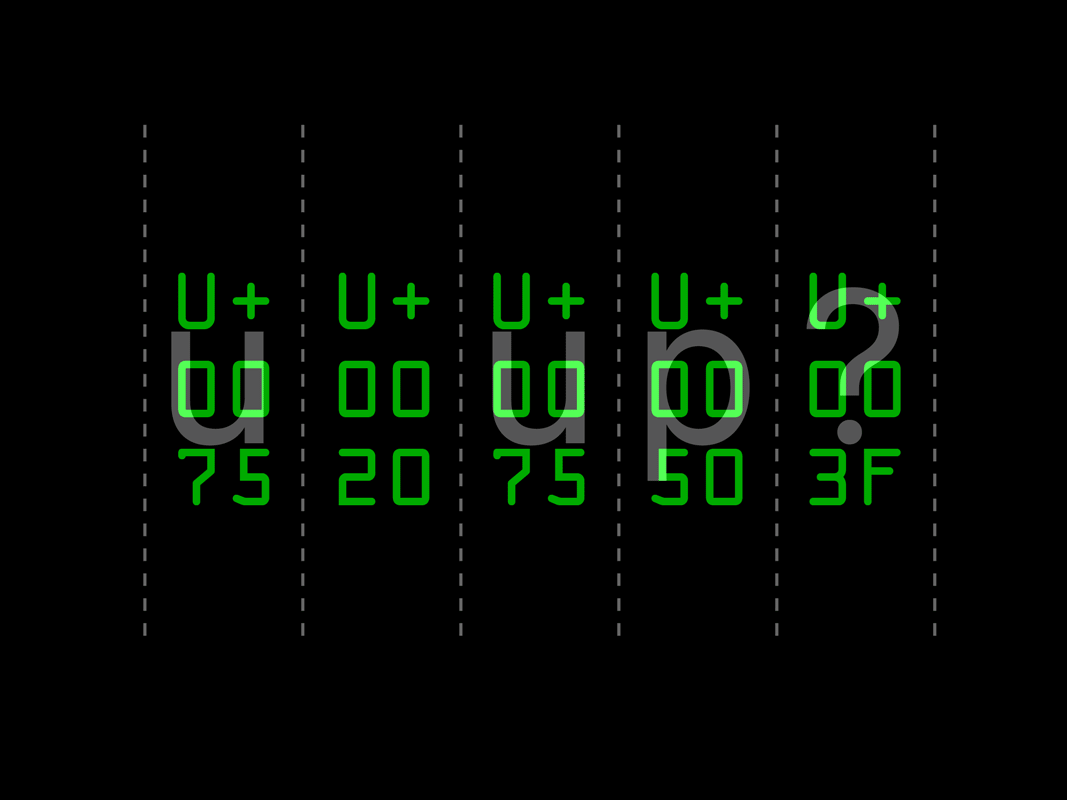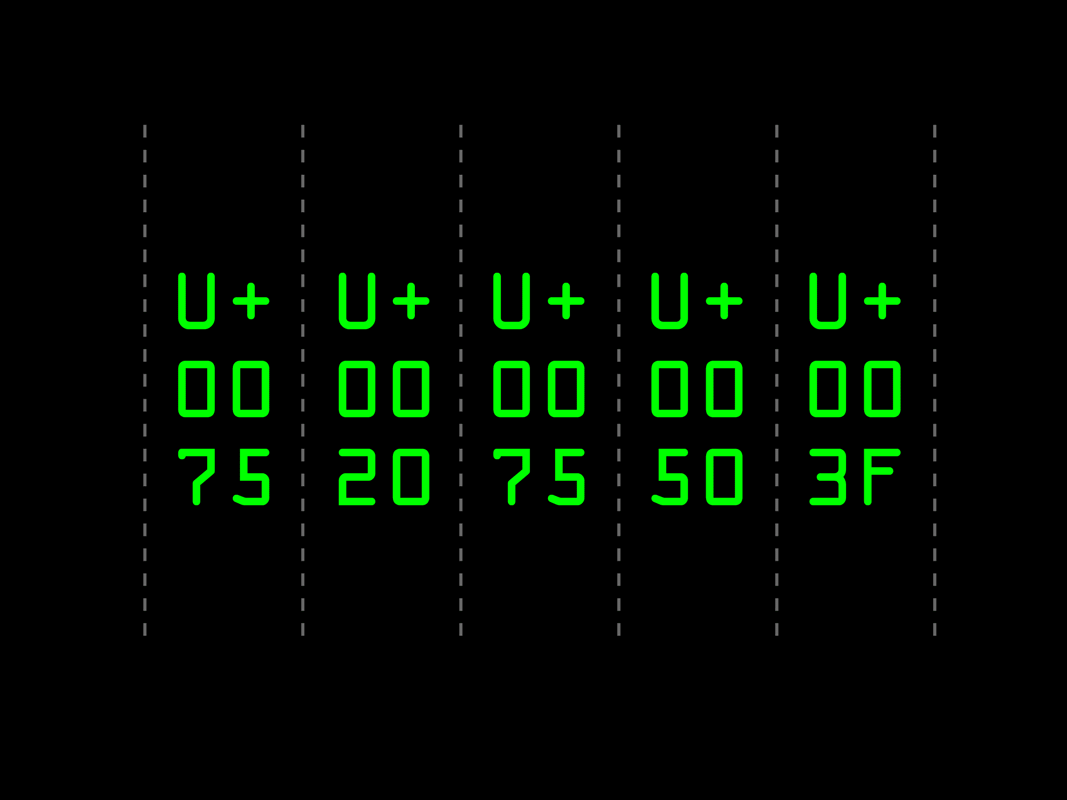
In digital-to-digital legibility, algorithimic readers parse a text sequence and convert letters to their unicode values for processing

In the 18th century, the English philosopher Jeremy Bentham developed the concept of the Panopticon, a design in which a single guard could surveil all prisoners. Today, scholars and critics often use the Panopticon as a metaphor for the internet, emphasizing the rise of mass surveillance, data capture, and social media monitoring.
From Reading to Knowing
The Internet is woven together as a tangle of self-reinforced protocols optimized for parsing text. Online posts are perpetually available to web scrapers for purposes as varying as historical archiving, content moderation, and national security. Artificial intelligence models are routinely trained with the content that people post online. Digital platforms have sophisticated internal data correlation software designed to anticipate users’ future conduct and to increase engagement by catering content and customizing experiences based on precise interests. Feeds that used to show chronological updates from friends now show asynchronous suggested posts from influencers and businesses interspersed with ads. Imminently, content itself will likely be generated by diffusion image models that are fine tuned on users’ consumption patterns. Behaviors are calibrated as algorithmic profiles are turned into marketable assets to advertisers. There are, of course, third-party blockers and end-to-end encryption channels to avoid surveillance and being targeted by advertisers, but the persisting standard for digital communication is one that relies on data storage for future economic growth.
Whether sending an email or a DM over TikTok, it is safe to assume that data is collected, in many cases without our knowledge. This is the current nature of computation. Technologies today are built upon users knowingly and unknowingly giving up their data in exchange for digital convenience. This is the nature of many products: on the Internet, platforms monetize interactions between users, cataloging personal information as a commodity. With the rise of Large Language Models (LLM) for the processing of text, social media platforms are finding a new asset in their databases, some selling users’ interactions for use in training machines. As cultural critic Johanna Drucker put it: “the concept of data as a given has to be rethought through a humanistic lens and characterized as captured, taken and constructed.4https://dhq-static.digitalhumanities.org/pdf/000091.pdf”
In his seminal essay “Surveillance and Capture,” researcher Philip Agre distinguishes between two models of privacy where “surveillance” refers to the monitoring of specific targets and the centralized collection of information to specify potential targets and “capture” as the phenomena through which generalized data aggregation models people’s actions. While “surveillance” tracks interactions to retroactively punish behaviors, “capture” imposes the very limits of interaction by restructuring human activities through computational articulations. As early as 1994, when he wrote the text, Agre noticed the trend within industries to allow computers to track actions in real time. Aggregated data would provoke a higher degree of computational efficiency and thus lead to more prolific businesses. “A computer can only compute with what it captures; so the less a system captures, the less functionality it can provide to its users,” he wrote5Agre, P. E. (1994). Surveillance and capture: Two models of privacy. The Information Society, 10(2), 101–127. https://doi.org/10.1080/01972243.1994.9960162.
While Agre did not shy away from imagining how the gathering of information could have not only economic but potential social benefits, he also anticipated the ways in which human behavior would be conditioned through what he called a “grammar of actions”— the conditions made possible by machines. The background capturing of data seems like a less threatening form of monitoring, however structuring computation in response to tracking human activity results in determinations that fix subjects within the predetermined possibilities of infrastructural spaces. This is evident now as we learn to talk to machines, bending human language to their understanding with each prompt, while getting systems to speak back to us. Just as proposed by Berlo’s SMCR model, where behavioral influence underlines communication, we internalize capture rendering our actions so that they align to what is more susceptible to being captured. It’s the ergonomics of the system, not its users.
What has evolved within the structuring of communication is the active participation of unwitting receivers, whose interactions regenerate the structuring of reception channels, sometimes in real time. With an astronomical amount of indexable data, the scale in which machines are able to process language, and learn from that processing, has resulted in diverse research fields and industries that integrate computer science with linguistics. Algorithms now attempt to infer meaning out of large, unstructured bodies of text. Through the statistical recognition of syntactic and grammatical patterns, these technologies not only categorize text, but also process it in context as they aim to “understand” it.
In 2021, Apple introduced a feature allowing users to opt out of apps sharing their data with third parties.

Google Gemini-2 launch (2024)
An early application of Natural Language Processing was used to detect key terms and phrases that flag a message as spam. This type of filtering has been dramatically upgraded to the point where Gmail, for instance, recognizes the “intent” behind the emails you get and puts them into different categories (primary, social, promotions, updates, forums) for you to prioritize them. A per-user machine learning program detects multiple signals and organizes emails based on their contents and the probability that the user will perform an action over them. This includes predicting the “importance” of mail without explicit user inputs, however both the pre-processing of language and frequency of interactions among senders and receivers provide information about how likely they are to react to each other’s emails over a period of time. These models are personalized and updated frequently. Your opening of an email and replying to is actively training the system. Now, inboxes can be delegated to artificial intelligence to summarize emails and draft responses. In 2024, Gmail incorporated Gemini, a generative chatbot developed by Google that was widely criticized after it repeatedly produced historically inaccurate images.

Example of a historically inaccurate images produced by Gemini
What is natural for people is difficult for computers since meaning is defined by incalculable contextual factors not directly present in text. In the same way that the decoding of a message involves psychological frames of reference and includes past life experiences as well as values and beliefs on the part of the receiver, computational systems too are idiosyncratic. Their outcomes are the product of numerical analysis inherently limited by the features of the given data which is in turn the product of capture mechanisms with their own identifiable biases. These systems require averaging and sampling procedures that inevitably compromise the subtle thresholds between “processing” and “understanding,” and the nuances that produce meaning as words structure into sentences and into larger arguments. In order to get closer to some form of “coherency,” computers mitigate the inconsistencies (i.e. creativity) that ultimately provide natural intentionality to person-to-person exchanges.
Languages are highly dynamic and the relationship between words and what they represent is elusive, permanently being molded by accidents, use, and (mis)interpretation. Computers, however, work from the premise that “knowledge” can somehow surface and be distilled mathematically, as if it would already underline accumulated data. The contrast between these modes of legibility is troubling when you consider the influence of capture algorithms in contemporary communication and the profit-driven decisions behind their architectures. As Agre wrote “The resulting ‘technology’ of tracking is not a simple matter of machinery: it also includes the empirical project of analysis, the ontological project of articulation, and the social project of imposition.6Ibid.”
By following what websites you visit and the links you click, Google became the largest advertising company in the world, personalizing product recommendations and serving contextual and behavioral ads. Their search engine also uses NLP to engineer results based on past queries and as it aims to recognize not what you’re typing, strictly, but what you’re trying to find. If you use Google Chrome, you will likely see in the upper right corner of your browser your profile picture or name in a circle signaling you’re logged into the browser, something that happens automatically if you’re a Gmail user. Yet if you open a website on Firefox you can tap the shield icon to the left of the URL address bar and pull up a list of the blocked cookies that were being linked by Chrome to your Gmail profile by default.
A user logged in to the Chrome browser
It wasn’t until 2017 that Google stopped scanning emails in order to sell targeted advertising. Years after privacy advocates continuously expressed their concerns, the suspension of this practice was done only in order to roll out their G Suite products for businesses. It was the potential privacy affections of corporations that pushed them to stop eavesdropping. “Some of the regular people who use Google services disliked the way their email contents were being used to target ads way back in 2004 […] Yet their concerns couldn’t get much traction until Google became aware 13 years later that some current or prospective paying enterprise customers were uncomfortable with this practice,” Seth Schoen, a senior technologist at the Electronic Frontier Foundation told The New York Times. While it might not be parsing your email contents per se, Google continues to display ads in Gmail based on what it knows about you from other means. Gmail still captures metadata, which includes subject lines and information on who and when you are communicating with.
Various ways Google has integrated Gemini AI into Gmail
How transparency and opacity can be used as forms of power or resistance
The Right to Opacity
We could demand greater degrees of transparency from technological black boxes. People, of course, deserve access to the logics behind the mechanisms that govern sociability. But the scrutinizing implications of cultural transparency has historically been a function of the dominant civilizing project under its preconceived ordering of clear universalisms. While we can stand against the opacity that companies instrumentalize to protect their products and compete within markets, we should also wonder how the claim for transparency has been wielded historically to homogenize cultures. As the means to generate and interpret language are monopolized, we can disconsent from systems that neutralize language in their attempt to synthesize it to its programmatic image. In a context where meaning is calculated—engineered—by those that control communication platforms, illegibility might serve as an ontological path towards diverse forms of cultural autonomy. The matter, then, that brings us together in this text is: how does unintelligibility challenge those in power?
The late Martinican philosopher and poet Édouard Glissant famously declared a “right to opacity.” His work confronts the devastating colonial history of the Caribbean, appealing to an ethics of becoming illegible by calling into question the etymological meaning of comprehension as an act of cultural capture. “In this version of understanding the verb to grasp contains the movement of hands that grab their surroundings and bring them back to themselves. A gesture of enclosure if not appropriation,” he wrote7Glissant, Édouard, 1928-2011. Poetics of Relation. Ann Arbor :University of Michigan Press, 1997.. Within the process of globalization, Glissant believed that the aim of transparency corresponds to a historical measure by which differences become distinguishable and quantifiable across comparative “ideal” scales, resulting in the normalizing of languages and threatening heterogeneous realities. Contrary to this, he defended a “chaos-world” of unsystematic relations where the clouding that characterizes cross-cultural exchanges beyond the rationalist imperial project, becomes the least violent way of communicating.

An Antillean Creole traffic sign which can be translated to “Lift your foot (slow down). Children are playing here!”
By emphasizing language, Glissant gave his ethics an aesthetic dimension. The francophone writer argued that dominant languages, such as French, benefit from the friction with what he called “subversive languages,” those compromised by the “give-and-take of sudden innovation,” such as the speaking of Creole in the Antilles or the Indian Ocean. French, he would explain, is dedicated to literary clarity with a reputation for seeking a rationality composed of “consecutive, noncontradictory, concise statements8Ibid..” This presupposed essence of uniformity in the context of oppressed French-speaking populations became the compass for revealing contrasting social hierarchies. The tangential linguistic relations we see in Creole, then, are not only culturally enriching, but produce opacity, and a poetics of compromise, that resists the risk of neutralizing differences through comprehension.
Most computational languages, by contrast, respond to the demands of efficiency: the potential to streamline processes within pre established operating systems. There are expectations and recursive affectations as platforms incorporate novel ways to apply code, but ultimately these languages turn meaningful by the degrees in which they are governable within networked protocols. To go back to Philip Agre’s warnings on computational capture, language needs to be subjected—susceptible—to being collected in order to be suitable for computational efficiency. The Unicode system serves its purpose only as it spreads as a ruling standard. How can we, then, avoid the rationality of the machine?
It should be noted though that computational processing might already be characterized by a degree of complexity that far exceeds our capacity for abstraction. Indeed machines are highly obscure and they will be increasingly so. We wonder when we should demand transparency, when should we claim a right to remain opaque? Our technical literacy might never satisfy computational speed and should not be thought of as an alternative to the regimes of transparency. Instead, moving towards entanglement — towards Glissant’s “chaos-world” word where languages and cultures are not reduced to computationally efficient versions of themselves — might require the edges of analog-digital transitions to remain not only compromised but compromisable. If seeking to navigate the murky waters of engineered opacity and to erode the current ordering of communication, it would be in a dynamic matrix of legibility, where messages become contingent on their capacity to be interpreted by multiple intermediaries at varying material stages. It is only in this wealth of frictions and reciprocal bifurcations that we can appeal to what Glissant described as “the mutual mutations generated by this interplay of relations.”9Ibid

